Polynomial fitting#
import numpy as np
import matplotlib.pyplot as plt
Let’s consider the example of fitting a polynomial to some measurements of \(y_i(x_i)\) (ie. \(y\) measured at a set of points \(x_i\)). An obvious way to solve the normal equations
is to calculate the inverse of \(\mathbf{A^T}\mathbf{A}\) and write
For simplicity, let’s take a constant error \(\sigma_i\) for each point, so the \(\sigma_i\)’s cancel out of the equations (it’s straightforward to put them back in if you need to).
# first generate some data from a random polynomial
k = 20 # order of polynomial
n = 100 # number of data points
x = np.linspace(-2,2,n)
a0 = -1.0 + 2*np.random.rand(k+1)
poly = np.polynomial.Polynomial(a0)
y = poly(x) + np.random.normal(scale=0.0, size=n)
plt.plot(x,y,'.')
# Compute the design matrix
# A_{ij} = f_j(x_i)
A = np.zeros((n, k+1))
for kk in range(k+1):
A[:, kk] = x**kk
# Now do the linear algebra part
rhs = np.transpose(A)@y
lhs = np.transpose(A)@A
a = np.linalg.inv(lhs)@rhs
print("Polynomial coeffs, Fitted coeffs, Fractional error")
for i in range(k+1):
print("%13g %13g %13g" % (a0[i], a[i], (a[i]-a0[i])/a0[i]))
xx = np.linspace(-2,2,1000)
poly = np.polynomial.Polynomial(a)
yy = poly(xx)
plt.plot(xx,yy,'--')
dev = np.sqrt(np.mean((y-poly(x))**2))
print('rms deviation / max(y) = %g' % (dev/np.max(np.abs(y)),))
plt.show()
Polynomial coeffs, Fitted coeffs, Fractional error
-0.96775 1647.69 -1703.6
0.542287 -113.767 -210.792
0.85276 -853.757 -1002.17
0.0967043 68.1566 703.794
0.842487 221.74 262.197
0.637623 -28.9621 -46.4219
-0.82743 -114.691 137.611
0.424265 15.404 35.3075
-0.802969 50.2446 -63.5736
0.910581 -4.13127 -5.53696
0.924924 -10.3297 -12.1682
0.640554 1.46682 1.28992
-0.50631 0.628652 -2.24164
0.609591 0.574248 -0.0579789
0.0211072 0.00666731 -0.684121
-0.35979 -0.368268 0.0235626
0.424995 0.413736 -0.0264921
0.240582 0.242067 0.00617299
0.135369 0.136831 0.0108019
-0.911123 -0.9112 8.50062e-05
-0.535428 -0.535476 8.9198e-05
rms deviation / max(y) = 0.00110679
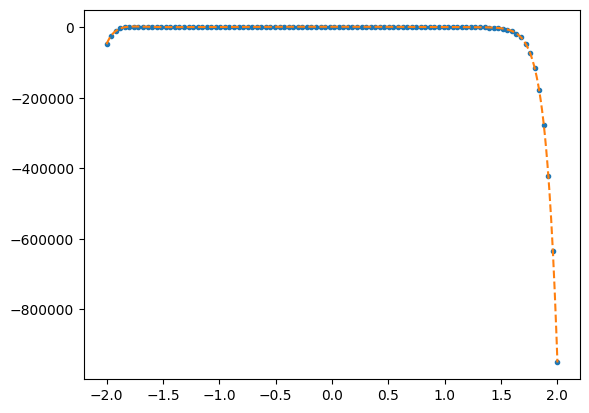
If you run this with no noise (scale=0 on line 10), you should see that for low polynomial order the coefficients are fit to machine precision, but the errors become large pretty quickly as you increase the polynomial order. Something is going horribly wrong with the matrix inversion as the polynomial order increases!
Using Singular Value Decomposition (SVD)#
Singular value decomposition (SVD) is extremely useful in these situations where you are dealing with a close-to-singular matrix. The ratio of the largest to smallest singular values is known as the condition number of the matrix, and measures how close to singular it is.
U, Sdiag, VT = np.linalg.svd(A,0)
# plot the singular values
plt.clf()
plt.plot(np.linspace(0,len(Sdiag),len(Sdiag)),Sdiag,'.')
plt.yscale('log')
plt.ylabel(r'Singular values')
plt.show()
print("Range of singular values = %g" % (max(abs(Sdiag))/min(abs(Sdiag))))
print("np.linalg.cond gives %g" % (np.linalg.cond(A)))
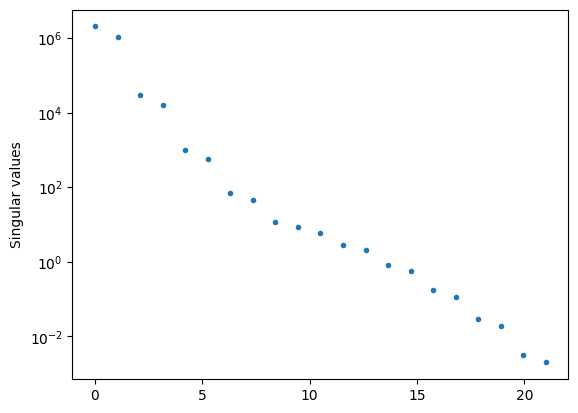
Range of singular values = 1.02088e+09
np.linalg.cond gives 1.02088e+09
Let’s use SVD to rewrite the normal equations:
The matrix \(\mathbf{VS^{-1}}\mathbf{U^T}\) is called the pseudo-inverse. We can use it to map from the data vector \(\mathbf{d}\) to the model parameters \(\mathbf{a}\).
# Find the model parameters using the SVD decomposition
aSVD = VT.T @ np.diag(1/Sdiag) @ U.T @ y
print("Polynomial coeffs, Fitted coeffs, Fractional error")
for i in range(k+1):
print("%13g, %13g %13g" % (a0[i], aSVD[i], (aSVD[i]-a0[i])/a0[i]))
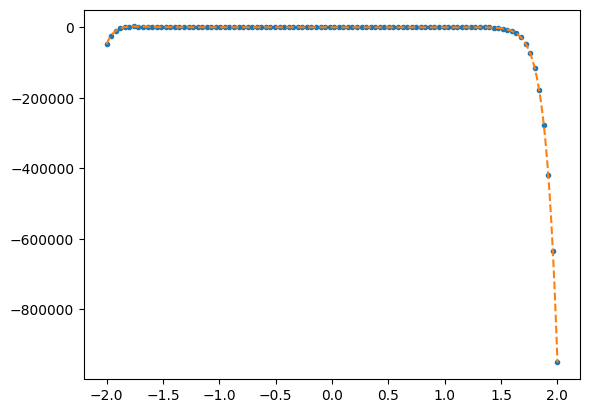
plt.plot(x,y,'.')
xx = np.linspace(-2,2,1000)
poly = np.polynomial.Polynomial(aSVD)
yy = poly(xx)
plt.plot(xx,yy,'--')
dev = np.sqrt(np.mean((y-poly(x))**2))
print('rms deviation / max(y) = %g' % (dev/np.max(np.abs(y)),))
plt.show()
Polynomial coeffs, Fitted coeffs, Fractional error
-0.96775, -0.96775 1.91324e-11
0.542287, 0.542287 4.34068e-11
0.85276, 0.85276 2.97942e-10
0.0967043, 0.0967043 -9.67429e-09
0.842487, 0.842487 -2.27761e-09
0.637623, 0.637623 7.23563e-09
-0.82743, -0.82743 -1.33468e-08
0.424265, 0.424265 -1.82184e-08
-0.802969, -0.802969 2.02189e-08
0.910581, 0.910581 1.05173e-08
0.924924, 0.924924 2.3907e-08
0.640554, 0.640554 -1.01385e-08
-0.50631, -0.50631 2.63536e-08
0.609591, 0.609591 2.80481e-09
0.0211072, 0.0211072 2.28063e-07
-0.35979, -0.35979 1.53938e-09
0.424995, 0.424995 -2.3327e-09
0.240582, 0.240582 4.0083e-10
0.135369, 0.135369 9.88322e-10
-0.911123, -0.911123 3.99992e-12
-0.535428, -0.535428 1.62548e-11
rms deviation / max(y) = 1.23244e-12
Orthogonal polynomials#
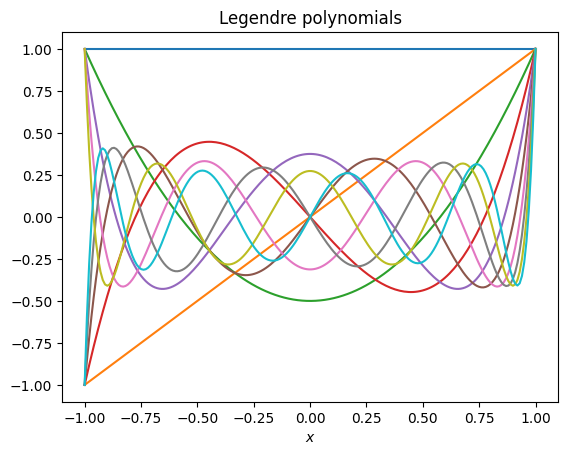
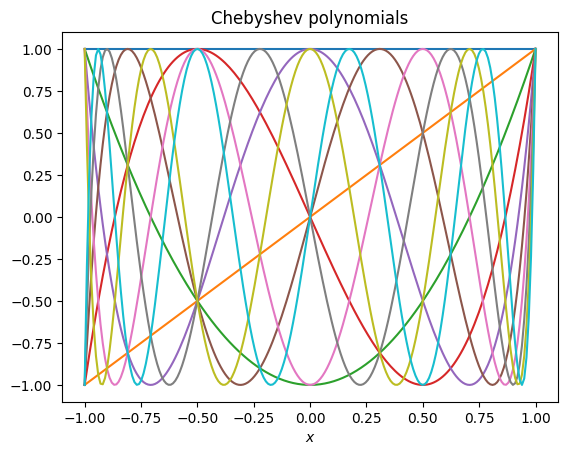
SVD does a lot better than straight inversion of the normal equations, but still fails for large enough polynomial order. One way that we can do better is to choose a set of basis functions that are orthogonal in the domain that we are interested in. For example, both the Legendre polynomials and the Chebyshev polynomials are orthogonal on the domain \(x=(-1,1)\) (which you can rescale to by rescaling your \(x\) variable).
# Plot the Legendre and Chebyshev polynomials
def plot_poly(poly_generator, title):
for i in range(10):
x = np.linspace(-1,1,200)
a = np.zeros(10)
a[i] = 1
poly = poly_generator(a)
plt.plot(x, poly(x))
plt.xlabel(r'$x$')
plt.title(title)
plt.show()
plot_poly(np.polynomial.legendre.Legendre, 'Legendre polynomials')
plot_poly(np.polynomial.chebyshev.Chebyshev, 'Chebyshev polynomials')
Exercise: Try changing the basis functions to Legendre polynomials or Chebyshev polynomials and see how that improves the fit, both for the inversion and SVD methods.
Things to investigate:
How do the results change when you change the number of data points, number of basis functions, and the order of the polynomial that you are fitting?
How different is the condition number of the design matrix with these new basis functions compared to what we had before (this will depend on the number of basis functions you use)?
Try fitting a more complicated function, e.g.
np.exp(np.sin(x**3)) + np.tanh(x)Hint: You can use
numpy.polynomial.legendre.legvanderandnumpy.polynomial.chebyshev.chebvanderto generate the design matrix \(\mathbf{A}\) for you.
Notes and further reading#
If you try fitting a large order polynomial with and without SVD, i.e. a case with very large condition number, you should see that the coefficients returned by SVD are much better behaved. With the straight inversion, successive coefficients often take on large positive and then negative values, to cancel out the contributions from successive basis functions. With SVD on the other hand, these coefficients tend to small values. For more on this, a good place to look is Numerical Recipes, sections 2.6 (on SVD) and 15.4 (for its use in linear least squares).
The Chebyshev polynomials have the interesting property that they have maximum or minimum values of \(\pm 1\), which makes it easy to assess the errors when approximating functions with a finite number of terms in the Chebyshev expansion. For more on this, look at section 5.8 of Numerical Recipes.